光电效应是一个非常著名和有历史意义的实验:在能够真实地用单光子做实验之前,这个实验就逼迫物理学家们用单粒子的视角来看光(当然,后来的进一步研究证明其实把光看成波也能够解释光电效应实验,只需要把电子的部分采用量子力学,可以Wikipedia “光电效应”)。那么,为什么是这样的呢?
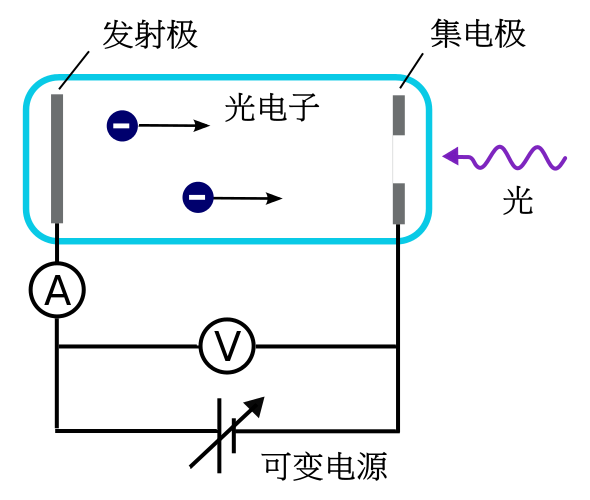
这是光电效应的实验装置示意图。两片连着电源的金属板构成一个腔,光照到其中一片金属板上。当光的频率比较合适的时候,就可以测量到电流——意味着有电子从左边的金属板跑到了右边的金属板上。那么,这个电子是从哪里来的呢?这个电流的强度和电压的大小和方向、光的频率和强度有什么关系呢?这样的关系怎么理解呢?
实验发现,对于给定的金属,只有光的频率大于某个值的时候,才会有电流,不管用多强的光来照,也不管什么样的电压。也就是说,单纯改变光的强度或者电压的大小和方向,不会把没有电流的情形变成有电流的情形。如果我们按照经典波来理解光,则光的强度可以看作是介质上振动的幅度的大小。大的强度就意味着大幅度的振动,于是,就会使得电子更容易被从金属中打(激发)出来。为什么改变强度会不起作用呢?
接着,实验还发现,对于能够产生电流的光,如果我们改变电压的大小和方向,则存在着饱和电流和截止电压。饱和电流的意思就是无论我们从正面——也就是帮助电子从一个金属板跑到另一个金属板的情况——怎么加强电压,只要电压大到一定程度,则电流不再增加。在那之前,电流会一直增加。截止电压的意思是,如果我们反过来加电压,也就是阻碍电子从一个金属板跑到另一个,则当电压到达一定大小之后,电流消失。在那之前,电流会逐渐减小。也就是下图的效果。a,b,c对应着不同的光强度。我们先不管。我们仅仅盯住其中一条线来看,例如a。x轴最左边就是截止电压。y轴最上方就是饱和电流。
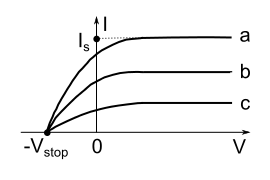
为什么会出现饱和电流和截止电压呢?饱和电流意味着从金属里面跑出来的电子已经完全都到达对面的金属上面去了,没有浪费。截止电压意味着从金属里面跑出来的电子一个都没有达到对边的金属上面,全都被电压(电场)阻碍了。也就是说,外加电压的改变,不会对跑出来的电子的数量有影响,仅仅改变的是电子是否容易到达对面。
这个时候,我们问,这个截止电压和什么东西有关系呢?给定金属的条件下,截止电压仅仅和光的频率有关系,和光照强度没有关系。实际上,改变光照强度的话,在给定金属和光的频率的条件下,仅仅会改变饱和电流,不能影响截止电压。于是,这个就更加说明了把光的强度看作是振动幅度的大小——这样就会更加容易把电子激发出来,是错的。
当然,正面的解释为什么需要把光子看作是一个个小球才能够理解这个现象是比较难的。不过,顺着这个光的小球的模型来解释这个现象倒是比较容易:光是一个个的小球,其本身的能量状态由其频率所决定,光的不同的强度对于给定频率的光来说表现为单位时间里面通过一个截面的这样的光小球的数量不一样;电子需要依靠从光子那里吸收的能量来从金属里面跑出来。于是,当单个光小球的能量不够让电子跑出来的时候,就没有电流产生。另外,就算小球的能量够,但是,如果加上反响的电压,则电子的能量在运动过程中会逐渐降低,因此,只要反向电压足够大,则其能量在到达另一片金属之前就消耗完毕,则不产生电流。这个足够大的反向电压就是截止电压。相应地,饱和电流的产生,则是因为给定光强度和光频率,单位时间能够产生的电子的总数就是定的,于是,增加正向电压的作用仅仅使得这些电子全都能够跑到另一片金属上,而不能增加跑出来的电子。当然,如果光的强度大,则单位时间内这样的光子多,于是跑出来的电子也会多,于是电流强度大。
这样,通过把光看作是一群小球,每个小球带着一份能量,就解释了光电效应现象,并且还发现,把光看做是介质的振动于是光的强度就是振动的幅度,不能解释光电现象(再一次强调,其实,可以的,只要把电子的运动部分量子话,也就是说,光子量子化电子经典、光经典电子量子化、光和电子都量子化,这三种方式,都可以解释光电效应,但是,光经典电子也经典,这样的模型不能解释光电效应)。
在构造前面的解释的过程中,我们用到了一点电压、电场、电流的知识,但是,更多的是实验和测量(尤其是考察其他因素都不变仅仅变化其中一个因素的时候的实验现象,作对比)、联系和对比、用数学和逻辑来构建想得通的想的明白的模型。很多时候,对科学现象的理解确实依赖于科学知识,但是,最根本的,我们需要的是去问一问为什么,去想一想是不是想得通。