今天偶然看见了14年前我自己编写的基于CCT的《中文LaTeX模版》被改成了CJK模版。现在,我把它再一次改写成为跨平台(Linux,Windows,MacOS)的版本,同时支持CJKLaTeX和XeLaTeX。
可以从以下链接下载:吴金闪《中文CJKLaTeX(XeLaTeX)模版》
有意思。
Jinshan Wu, a relational and critical thinker
今天偶然看见了14年前我自己编写的基于CCT的《中文LaTeX模版》被改成了CJK模版。现在,我把它再一次改写成为跨平台(Linux,Windows,MacOS)的版本,同时支持CJKLaTeX和XeLaTeX。
可以从以下链接下载:吴金闪《中文CJKLaTeX(XeLaTeX)模版》
有意思。
见http://www.bbc.com/future/story/20130315-a-better-way-to-learn-chinese。述评写的非常好,比我们的文章的Introduction还要好。Philip Ball是牛人一名(Critical Mass等书的作者)。
顺便,把我们汉字的工作也在这里总结一下。
在这个用系联性思维和网络分析研究汉字学习的工作中,我们主要关心以下两个问题:第一、对于一个或者一类学习者来说,用什么顺序学习汉字学习效率会更高;第二、如何高效率地检测一个学习者认得哪些汉字。实际上,在这个工作中,我们仅仅完成了第一个问题的一部分。当然,数据和研究方法都可以用来研究第二个问题。
如果每一个汉字是独立的,那么,最好的顺序就是按照汉字的使用频率来学习:使用频率越高的汉字越早应该被学习。这样的话,经过一段时间的积累,我们就可以通过自己看书学习的方式来学习新的汉字。但是,汉字是独立的吗?
不是的,汉字的音形义之间有联系,不同的汉字之间也存在音形义的联系。例如,“木、林、森”,一棵树(木),聚在一起是一堆树(林),大范围聚集是一大片树(森)。。再例如“秉”是手、禾的结合表示“拿在手上”的含义,“兼”是并(两个禾苗)、手的结合表示“一手拿着两个禾苗也就是两样东西”的含义。通过字形的联系,我们看到了含以上的联系。
顺便,我们可以看到,如果我们先学习木,再学习林和森,以及先学习禾、手,再学习秉,接着学习兼,就可以很容易学会这些字。反过来,如果打乱这个顺序,或者说,每个字都单独记忆,则学习成本会高很多。同样地,如果你不认识木,我可以以很大的概率推测你也不认识林和森,或者反过来你认得森,我可以以很大的概率推断你认识林和木。这就是我们在下面的整个研究工作的最朴素的思考地点。
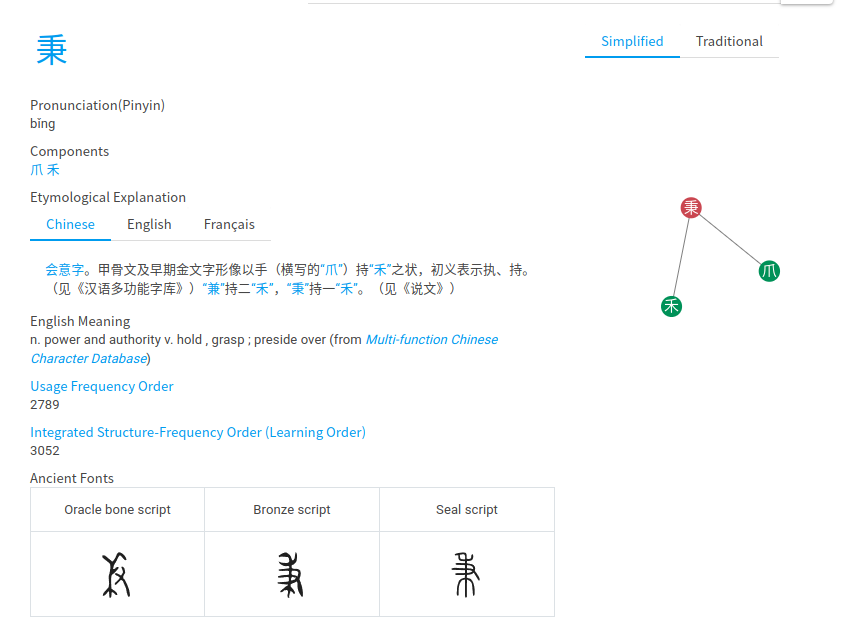
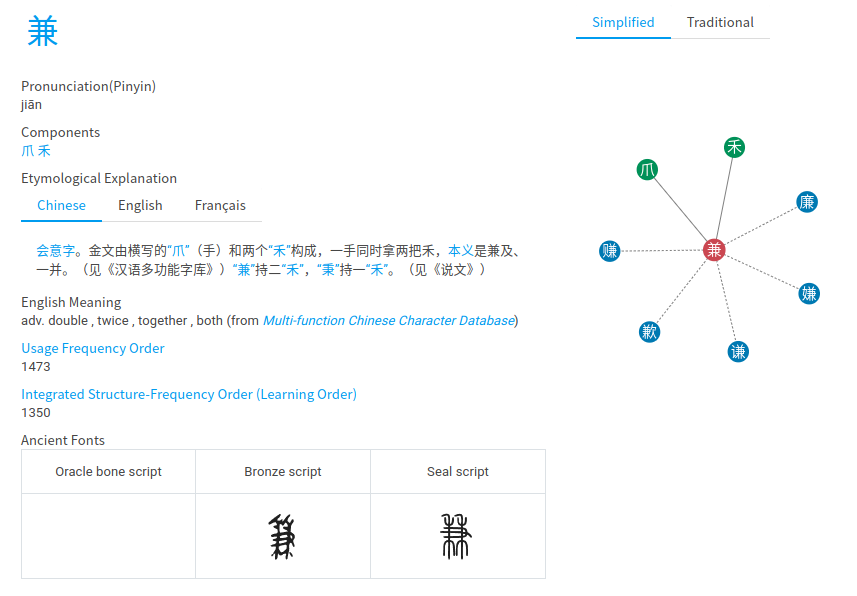
那么,既然汉字之间是相互联系的,汉字的音形义也是相互联系的,汉字学习和汉字检测是否能够利用上这样的联系呢?这时候,我们就需要把这些联系用一个数学结构来描述,然后,最好这个数学结构还能够帮助我们来解决更好的汉字学习顺序和汉字检测方法的问题。
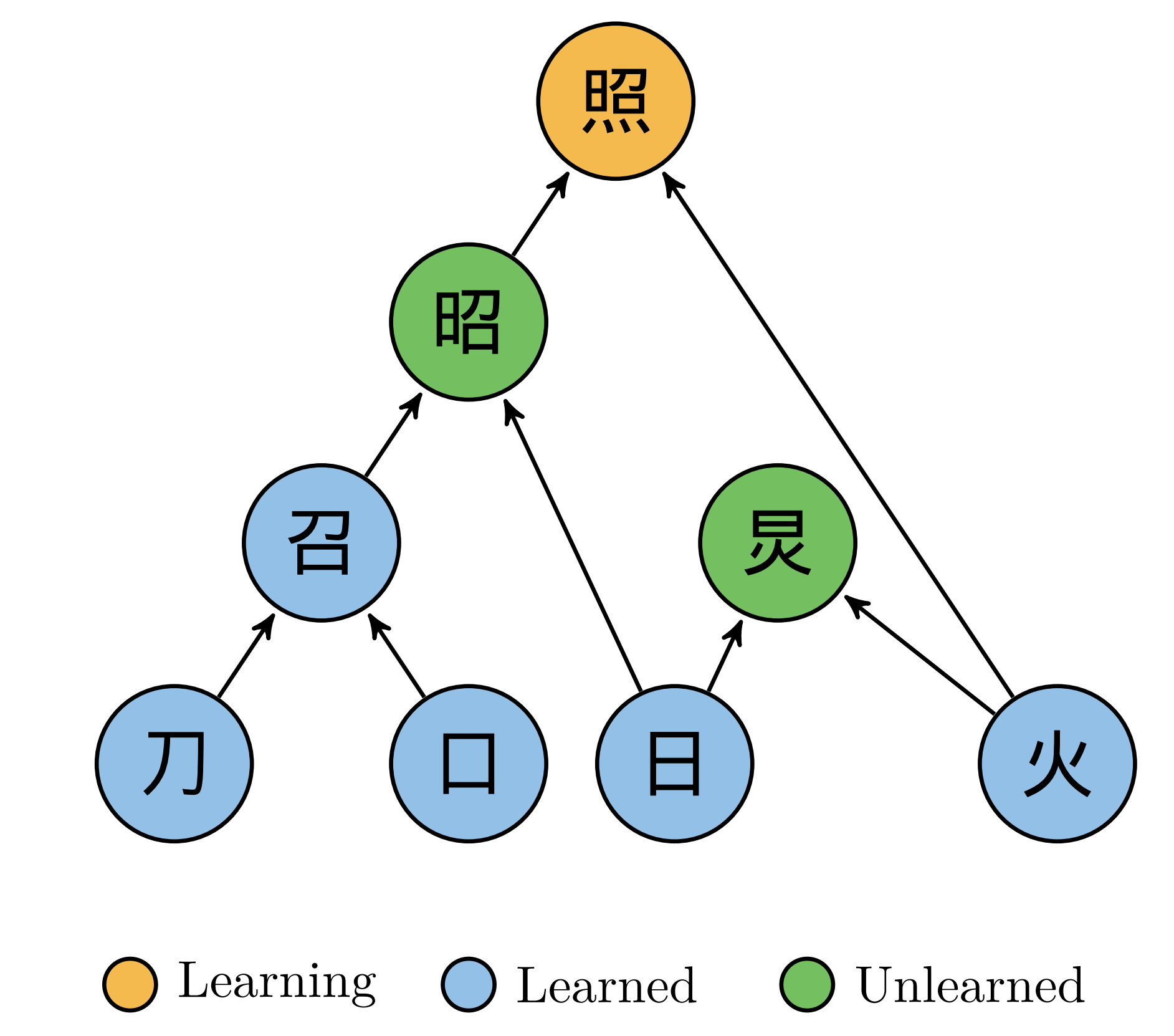
在我们的论文中,我们用了“网络”这个数学结构来描述汉字之间的关系。例如,下图就是“照”的一个局部的网络。我们做了直接联系的拆分,并且保持拆分出来的每个部分还具有表达音或者义的作用。注意,这里的拆分不是偏旁部首拆分,也不是笔画拆分。我们称之为汉字的理据性拆分。
有了这个拆分的原则之后,我们就可以对所有的汉字做拆分,得到汉字结构地图(这个基础数据是四人年的工作量哦,而且我们都仅仅是做整理——把前人研究好的每一个字到底应该如何拆分有什么道理整理成比较有系统的一个数据库——而已),见下图。
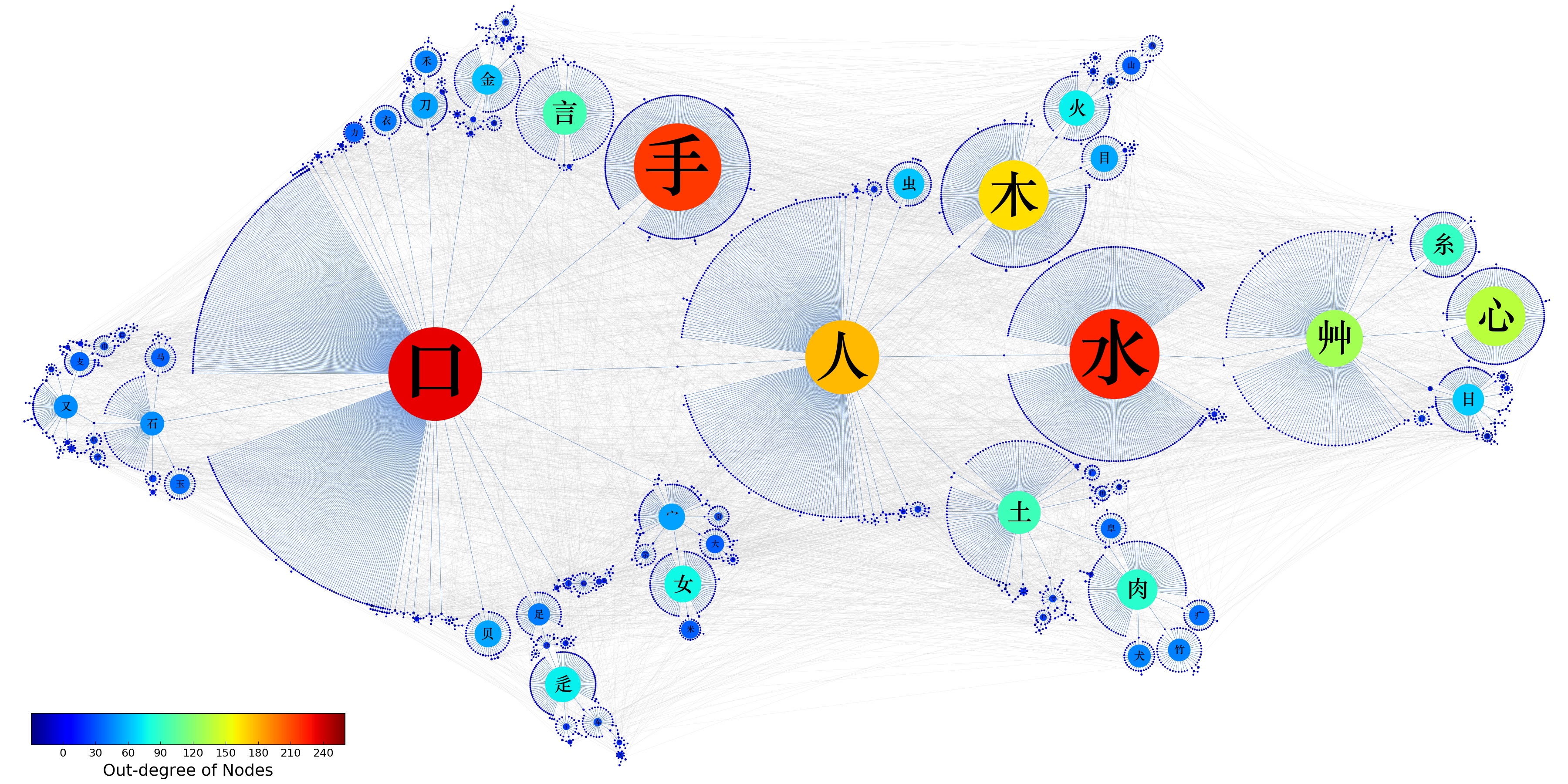
那现在有了描述汉字联系的数学结构(记做矩阵\(A\),其中元素\(a^{i}_{j}=1\)表示汉字\(i\)成了汉字\(j\)的一部分,否则\(a^{i}_{j}=0\))了,这个结构能够帮助我们通过计算来解答前面的两个问题吗——更好的汉字学习顺序、更好的汉字检测算法?直觉上来说,在汉字学习上,我们需要一个“学习了汉字A可以帮助我们更容易更好地学习汉字B”的关系,比如说,写成\(C\left(B=0\rightarrow B=1|A=1\right)\),以及更加一般的多个汉字之间的学习上的依赖关系\(C\left(B=0\rightarrow B=1|A_{1}=1,A_{2}=1\right)\)。直觉上来说,在汉字检测上,我们需要一个“检测得到汉字A认得(不认得)可以推断出来汉字B认得或者不认得的概率”,比如说,写成\(P\left(B=1|A=1\right), P\left(B=0|A=1\right), P\left(B=1|A=0\right), P\left(B=0|A=0\right)\),以及更加一般的多个汉字之间的是否认得上的依赖关系\(P\left(B=1|A_{1}=1,A_{2}=1\right)\)等等。
这个依赖关系可以从上面的汉字结构地图或者说汉字网络上得到吗?大概来说可以。我们可以把连边连起来的汉字这样来看:学习下一层的更简单的汉字可以帮助我们降低学习上层汉字的成本(具体如何降低是另一个问题),这样就大概得到了\(C\)函数;如果检测了下层汉字不认得,则上层汉字以很大的概率可以推断不认得,检测了上层汉字认得,则下层汉字以很大的概率可以推断认得,这样就得到了\(P\)函数。由于学了基本字可以降低学习复杂字的成本,这样的\(C\)函数有一个特性:从底向上学起来节省成本,跳着学成本更高。
有了这两个函数,原则上,我们就成了一个数学题:给定任何一个学习顺序,我们可以计算出来从成本;给定一个检测顺序(检测算法),我们可以计算出来需要检测多少次才能达到某个误差范围内,于是下一步就是一个优化问题:既然成本都能够计算出来,则,是否存在并且能够(近似)找到一个最优的学习顺序和检测顺序(检测算法)。
在这个工作中,我们用一个近似方法——顶点权传递方法(后来我们发现这个方法是广义投入产出分析的一种,和PageRank类似)——求解了第一个问题。我们把我们的算法得到的学习顺序的度量称作“分布式顶点权”。其基本思想特别简单:给每一个汉字一个原始顶点权——其使用频率(\(W\));从最上层开始,把原始顶点权往下传播到它们的下一层,传播之后,下一层的分布式顶点权(\(\tilde{W}\))等于其原始顶点权加上从上面传下来的那些乘以个系数,然后继续传递到下一层,也就是
\begin{align}
\tilde{W}^{i}= W^{i} + \sum_{j}\frac{a_{i}^{j}}{\sum_{k}a_{i}^{k}}\tilde{W}^{j}.
\end{align}
或者说用更简单的记号,记\(B^{i}_{j}=\frac{a_{i}^{j}}{\sum_{k}a_{i}^{k}}\),则
\begin{align}
\tilde{W}= W+ B\tilde{W} \Rightarrow \tilde{W}= \left(1-B\right)^{-1}W.
\end{align}
注意这个公式跟论文中不完全一样,时候来根据广义投入产出分析的思想修改过的公式。
有了这个算出来的“分布式顶点权”,我们就可以给所有的汉字排个序,权大的优先学习。于是,就得到了一个可能比较好的学习顺序。注意,我们没有去求精确解,这个解是基于一些简单理念猜出来的。这些简单理念包含:越下层的简单字应该越优先学习,使用频率大的字优先学习,参与构字数量多的字应该优先学习。我们猜出来上面的传播计算正好符合这三个理念。
那,怎么检验呢?原则上要通过实践检验,因为前面的学习成本函数\(C\)也是不可靠的。但是,只要有了\(C\)函数,我们就可以理论上先来比较一下几个不同的学习顺序,例如,不同教材上的学习顺序,我们算出来的顺序。于是,我们得到了下面的两张图。我们发现。无论是以总字数还是总使用频率为目标,我们的分布式顶点权的顺序学习效率都比较高(成本比较低)。当然,如果仅仅看字数,则从底向上学习肯定是最节省成本的,但是,可能会学习一大堆非常用字;如果仅仅看使用频率,则按照使用频率学肯定不差,西瓜先捡大的吃。但是,我们算出来的顺序竟然在两方面都不差,甚至,在使用频率上,由于照顾了上下层关系,比其他的都好。当然,你会发现,实际教材的,远远赶不上这些理论模型。这说明,这些实际教材在设计的时候基本上没有考虑汉字学习顺序的问题。

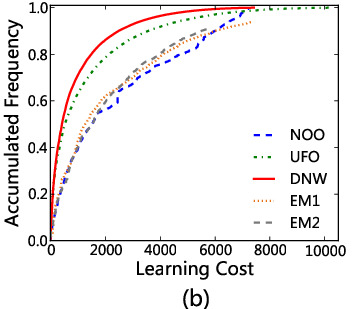
当然,你说,这个\(C\)函数和\(P\)函数不够准确。是的,这个显然还可以继续提高。例如,是不是学习了上层汉字以后也可以降低下层汉字的学习成本,只不过可能效果没这么强?这些因素都可以在汉字网络的框架内进一步考虑进去。
甚至,更进一步,我们注意到实际上汉字学习和汉字检测的关键数学表达式非常像条件概率。考虑到汉字之间没有结构关系也可能会存在相互启发的作用,因此,汉字网络这个数学结构用来描述上面的\(C\)函数和\(P\)函数其实还不够。更好的数学结构是概率图模型。目前,我们正在开展这方面的研究。将来,通过实际汉字检测得到的汉字结构数据正好可以和这里的纯结构网络做一个对比。我相信,两个结构还是应该有很大的相同的部分的。
更加一般地,我们猜测,如果我们把所有的学科的概念都整理成为概念网络,或者说概念地图,则,我们可以用类似的方法来研究更好的学习顺序和更好的检测方法的问题。
我们看到,如果我们忽略这个汉字之间的、汉字音形义的联系,甚至进一步忽略汉字的使用频率,则,我们只能一个个随机地来学习汉字,一个个随机地来检测汉字。也就是说,我们对汉字这个集合的描述确实更简单了,无相互作用系统,但是,我们对于解决汉字学习和检测的问题的方法却也就更愚蠢了。
这个研究工作的原始数据、计算结果、完整的汉字联系(理据性)的解释见www.learnm.org。已发表的论文在这里:Xiaoyong Yan, Ying Fan, Zengru Di, Shlomo Havlin, Jinshan Wu, Efficient learning strategy of chinese characters based on network approach, PloS ONE, 8, e69745 (2013) DOI: 10.1371/journal.pone.0069745.
刚才跟红刚聊天,讨论中国学生学英语。基本上大学生除了上课、做作业就是交朋友学英语。这些事情本身独立来看都是很好的事情。但是,一个好学生通常花40%左右的时间在学英语。中小学生学英语的时间稍微少一点,但是一般也是最主要的课外课程。
我认为英语是要好好学的,尤其是做科学的,做社会科学的,做社会管理工作的,设计制度的,因为我们在这些方面都需要向英文界好好学习。但是,剩下的(他们的总数远远多于上面提到的),学英语应该当作业余爱好。
因此,我建议,英语在所有的学校水平只能作为选修课开设,但是某些专业的研究生入学考试要考英语,少数专业的本科入学考试要考英语。
语言的学习方式永远是交流,目的大部分也是交流。不按照这个原则,就是胡教乱学。
顺便,这里是我英文授《量子力学》课的视频。
如果政府在颁发结婚证的时候让你填写你的所有情感生活经历,你会觉得怎样?
我们最近要求填的工会表格要求填写姓名、职称、省份证号码、身份证起止日期,等等信息。第一,这些信息在人事处系统(非常强大的数据库系统,部署在人事处内部网络上)里头都有。我不明白为什么工会要再搞一套,更不明白为什么工会不能从人事处获得?办公系统的设计就是为了数据共享,而且可以设计权限,不同的子系统能够接触不同的数据。第二,要身份证起止日期做什么用?
填过任何有底线的国外政府部门的表格,你就会看见一个说明:大意是,我们认为这些信息是必要的,大约需要耗时多少,如果你认为信息要求不合理,请你向某某部门报告。
不能因为你有权利颁发结婚证,你就可以问性生活,问交往历史,你要问,我设计的表格要求的信息是完成我的决策或者服务必需的吗?
这个事情,和法律文书的“等等”、“其他事项”,实际上是一样的,叫做权利abuse(滥用?中文合适的词是什么?)。
这个事情实际上和360的行径的原则也是一样的。我要保护你的电脑的安全,所以,我要知道通常你什么时候拉屎拉什么类型的屎(因为这时候容易受到计算机病毒攻击)。
感冒要不要吃药?
·方舟子·
最近网上有人指控在中国使用人数最多的儿童感冒药“优卡丹”和“好娃娃”
对儿童有肝、肾毒性,引起了很大的风波。“优卡丹”厂商虽然出面否认“优卡
丹”对儿童肝、肾有害,但立即修改产品说明书,写明一岁以下婴幼儿应禁服优
卡丹。那么婴幼儿得了感冒怎么办呢?有没有必要服用感冒药呢?
感冒是病毒引起的急性上呼吸道感染,由流感病毒引起的称为流行性感冒
(简称流感),由其他病毒(多达一百多种,以鼻病毒和冠状病毒最常见)引起
的称为普通感冒。流感和普通感冒其实是两种不同的疾病,但因为症状相似,经
常被相提并论。要治疗感冒,就要能杀死或抑制引起感冒的病毒,也就是使用抗
病毒药物。但是目前并没有能针对普通感冒病毒的抗病毒药物,针对流感的抗病
毒药物倒是有,例如磷酸奥斯他韦(商品名达菲),但作用也很有限:如果在流
感症状出现的早期使用,可以缩短流感病程大约2天并减轻症状。所以一般也用
不着。而且达菲是处方药,患者自己在药店是买不到的。
患者自己能买到的非处方感冒药,都不能“治本”(抗病毒),而只是“治
标”,缓解感冒症状,让患者感觉舒服一些,并不能治愈感冒或缩短病程。感冒
药的品种虽然繁多,但是有效成分都不出这几种:解热镇痛药对乙酰氨基酚(也
叫扑热息痛)用于退烧和缓解头痛,抗组胺药马来酸氯苯那敏(也叫扑尔敏)或
苯海拉明用于减少鼻粘液分泌和缓解鼻塞,伪麻黄碱用于减轻鼻粘膜充血,右美
沙芬用于止咳。
中国比较特殊的是还有形形色色的中药感冒药,除了麻黄能够减轻鼻塞(西
药感冒药中麻黄碱最早就是从麻黄提取的,但现在都改用副作用更小的伪麻黄
碱),并没有哪一种被证明了对感冒有疗效。如果中药感冒药有些效果,是添加
了上述化学药成分。中药感冒药尤其喜欢添加对乙酰氨基酚和马来酸氯苯那敏,
有的注明(例如“维C银翘片”),有的没有注明,但经常被香港、台湾和外国
药监部门查出偷加了西药成分。
所以你在药店买到的感冒药其实没有一种是真正能治愈感冒的。但感冒是自
限性疾病,过一、两周自己就好了。如果忍受得了,完全没有必要吃那些缓解症
状的感冒药,注意多喝水和休息即可。忍受不了,吃点缓解症状的感冒药也行,
但这些感冒药并不真正治病。
中国医生治感冒时还喜欢开抗生素,甚至是用静脉注射的方式使用抗生素。
“吊水”、“打点滴”治感冒,是只有中国才有的怪现象。抗生素只能抗细菌,
而感冒是病毒引起的,抗生素抗不了病毒,所以使用抗生素是治不了感冒的。有
的医生辩解说,用抗生素治感冒是为了防止并发细菌感染。感冒虽然有时能并发
细菌感染,但是使用抗生素并不能有效地预防这类并发症。
回头再来看看“优卡丹”和“好娃娃”。它们实际上是不同厂家生产的同一
种药,通用名称叫小儿氨酚烷胺颗粒,其成分为:对乙酰氨基酚、盐酸金刚烷胺、
人工牛黄、咖啡因、马来酸氯苯那敏。其中人工牛黄是“解热、镇惊”的中药,
其实没有任何效果。咖啡因是中枢兴奋药,是提神用的。盐酸金刚烷胺是抗病毒
药,但它抗不了普通感冒病毒,以前能抗流感病毒,但是现在流感病毒对它的抗
药性已达到100%,对流感也没有效果了。所以“优卡丹”和“好娃娃”的真正有
效成分就是对乙酰氨基酚和马来酸氯苯那敏。如果觉得吃“优卡丹”或“好娃娃”
对感冒有效,完全可以自己去买对乙酰氨基酚和马来酸氯苯那敏来用,要便宜得
多,也安全得多,可以避免那些无效成分带来的不良反应。
而且“优卡丹”和“好娃娃”是针对儿童的感冒药,而美国食品药物管理局
警告2岁以下的儿童不能使用感冒药,美国非处方药行业组织自愿在感冒药上标
注“4岁以下儿童不能使用”,美国食品药物管理局专家委员会和澳大利亚药监
当局则建议6岁以下儿童不要使用感冒药。这包括减充血剂(例如麻黄碱、伪麻
黄碱)、止咳药(例如右美沙芬)、祛痰药(例如愈创木酚甘油醚)、抗组胺药
(例如马来酸氯苯那敏、苯海拉明)。这些药物对儿童没有效,反而有导致严重
不良反应的风险。在1996~2006年间,有54例儿童因服用减充血剂死亡和69例儿
童因服用抗组胺药死亡的报告。
如果儿童得了感冒,不吃感冒药,怎么缓解症状呢?有这些办法可以参考:
要退烧、缓解疼痛可以吃对乙酰氨基酚或布洛芬(中低度的发烧其实是不用退
的)。对乙酰氨基酚或布洛芬如果不过量使用,是非常安全的,所以要注意用儿
童剂量的,例如“小儿泰诺林”、“美林”。但是不到6个月大的儿童不要用布
洛芬(“美林”)。任何年龄的儿童都不要用阿司匹林解热镇痛,因为阿司匹林
对儿童有引起致命的雷依氏综合征的风险。减轻鼻塞可以使用盐水滴鼻液。多喝
水也可减轻鼻塞并防止脱水。鼓励儿童咳嗽,咳嗽能帮助清理呼吸道。吃冷饮能
缓解咽喉疼痛。多休息。如果空气干燥的话,使用加湿器。密切观察儿童症状的
变化,如果发现不寻常的状况(例如持续高烧、呼吸困难、排尿不正常等等),
即时就医。如果过了一周感冒还没有好或症状变得更严重,去医院查一下是否并
发了细菌感染,例如鼻炎或耳朵感染。
有的中国医生吓唬患者或儿童患者家长说,得了感冒不治疗、不吃药,当心
演变成肺炎。感冒虽然有时能并发肺炎,但这和治不治疗、吃不吃药没有关系,
并没有哪种感冒药能够预防肺炎。感冒在中国是被严重地过度治疗的,这是患者
的无知和医生的牟利相互作用的结果。多学一点医学知识,不仅可以少花或不花
医药费,更重要的是,避免因滥用药物带来的健康风险,对儿童尤其重要。
2013.1.30.
(《新华每日电讯》2013.2.22)
(XYS20130305)