汉字可以一个一个来记忆和学习,也可以在课文中通过理解其用法来学习。这个就是通常学生学习汉字的方法。在实际学习过程中,这种学习方法要付出大量的记忆性的努力,还有通过大量的重复练习来巩固。
对于中国人,这个不是大问题,因为,汉语是已经会的,能够认字和写字也就解决了大部分的问题了。
对于不会汉语的人来说,由于同时要学会汉字和汉语,两者的联系又不是很紧密(看到一个汉字不能很好地提示其含义和读音,还有用法)。以语言和词汇为主的学习方式导致汉字成了一个语言的简单的记忆单位。例如“单位”这个词,有可能英语背景的学习者直接就整体认知成为”unit”,而不能明白其实“单”是”single”的意思“位”是”unit”或者“position”的意思,更加不能明白为什么“单位”两个字合起来就能表示”unit”的意思。于是,也就不能迁移(例如理解“单身”——如果也能够拆分成“single body”的意思就很好学会了)。同样的情况可以发生在“汉语”这个词上。只有理解了“汉语”的内在结构才能明白“汉语、汉字、汉族、汉学”等等之间的内在联系。这个说的是在词汇的层次要注意构成词汇的汉字之间的联系,也就是词汇的联系。
汉语其实还有更加深刻的内部结构:汉字本身也是有内部基本单位的,这些单位也是通过某种联系有机地结合在一起的。例如“位”这个字,为什么是”position”的意思呢?其实,这是两个不同的部分“人”和“立”,合起来表示“人站着的位置”的意思。这个是汉字的非常重要的特征。一个好的学习者,或者好的学习方案就要利用好这个特征。
例如,“黑”这个字来源于把“器皿”放在“火”上烤。如果你干过这样的事情,例如小时候玩蜡烛,就知道什么是黑了。接着这个黑字,如果我们把这个积累在器皿上的黑东西扣下来,揉成一团,象“土”一样,就得到了“墨”。再例如,跋山涉水的“涉”,原来的写法(现在还能够稍微看出来一点点),是两个脚趾头的“止”放在“水”的两边,于是就是徒步过小河的意思。顺便出道题,“往”为什么不念“主”的音,而是念“王”的音啊?通过这些例子,我相信读者就可以体会到,一旦把字的结构如何拆分、为什么这样的拆分合起来可以表达这个字的读音含义,那么,这个字就容易学了,甚至学会了也更容易用了。也就是,学活了,效率高成本低了。
于是,这就有了两个问题:第一,这样的汉字内部结构的拆分和解释的基础数据我们有吗?第二,有了这个基础数据,我们能够如何帮助汉字学习呢?
第一个问题,其实是汉字研究内部的问题。不过,如果没有考虑到第二个问题的话,其拆分,当然也很有用,不一定能够满足后面的需求。幸好,在汉字的历史上这样的拆分是有的,例如《说文解字》,尽管还不够。
在汉字结构网络与理解型学习系统可以看到我们的拆分数据,以及分析计算的结果。这是一个大大的图: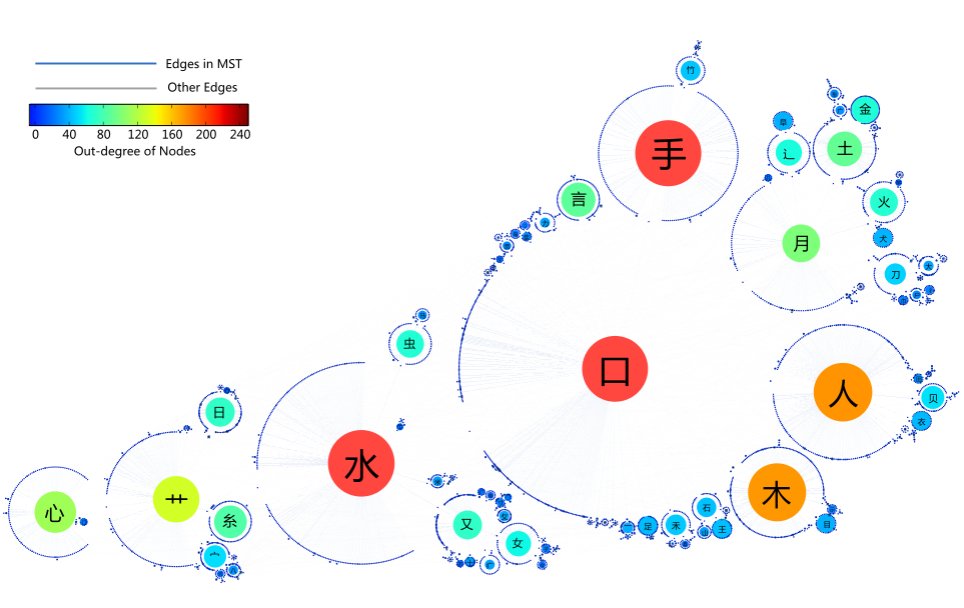
第二个问题,分两个层次。在个体的层次,有了这个基础的拆分,就能够促进汉字学习者做理解型学习,也就是明白汉字的结构以及从这个结构引申到含义和读音,从而减少记忆负担。在整体的层次,我们可以问类似这样的问题:我们应该先学习哪些汉字,后学习哪一些呢?我们如何快速低成本地检测一个学习者认识哪一些不认识哪一些汉字呢?两个问题还可以合起来,了解了这个学习者所认识的字和不认识的字以后,如何利用这个信息来促进汉字的学习呢?例如,很容易想到,学习那些跨度不太远的与已经认识的字有内在联系的字可能会更容易一些。
我们的研究实际上,主要关注这个整体性的问题,也就是学习顺序、高效检测方法、个性化学习顺序这几个问题。当然,与汉字研究专家合作,建设汉字结构基础数据库也是正在开展的一个工作。
长期来看,我们还需要把汉字和汉语结合起来,开发学习材料,利用篇章的学习来带动汉字的学习,而且这个汉字的学习还需要一定程度上照顾我们的理想中的学习顺序。学习材料的开发和实验应该是一个循环上升的过程。推广或者产品化也是需要考虑的问题,不过那是其他人的事情了。很多的周边产品也可以考虑,例如,在汉字结构数据的基础上,开发一个图片或者动画形式的识字产品。例如,把整个学习顺序和检测顺序,以及学习材料做成一个汉字学习系统(软件)。
在这个工作里面,系统科学的思想,体现在从个体层次的问题到整体层次的问题的思考问题的角度上。另外,在技术上,我们需要设计好的数学模型来解决学习顺序的计算,高效检测算法的制定。同时,系统科学还体现在把一个领域的问题研究的比较深入以后,可以迁移出来,或者把别的领域的方法迁移过来。也就是系统科学所关注的类似的系统存在的一般性。
例如,实际上,你会发现,汉字的这样的利用汉字内部结构和联系(同时也是汉字之间的联系)的方式来促进学习(学习顺序和检测的问题),同样可以用来学习数学、物理学等逻辑关系比较清楚的科学。甚至,如果能够把条理不清楚的学科整理出条理来,学习效果的提升程度,应该比条理清楚的更好。
实际上,这个工作里面提出和发展的思想就是我们提出的“教的更少,学得更多”的理解型学习教学的核心。
参考文献:
1、Xiaoyong yan, Ying Fan, Zengru Di, Shlomo Havlin, Jinshan Wu, Efficient learning strategy of chinese characters based on network approach, PloS ONE, 8, e69745 (2013).
2、科普作家Philip Ball在www.bbc.com/future上对这个工作的述评。
