对于一个的集合\(L=\left\{1,2,\cdots, i, \cdots, \right\}\)中每个个体的学习,如果给定了每一个学习对象的难度\(\vec{C}=\left\{c_{i}\right\}\)和价值\(\vec{V}=\left\{v_{i}\right\}\),我们的学习顺序\(\vec{S}=\left[s_{1}, s_{2}, \cdots, \right]^{T}\)的问题是这样定义的:
- 给定\(\vec{S}\)之后在第\(m\)步的累计成本为
- 给定\(\vec{S}\)之后在第\(m\)步的累计价值为
\begin{align}
C\left(\vec{S}, m\right) = \sum_{j=1}^{m} C_{s_{j}}
\end{align}
\begin{align}
V\left(\vec{S}, m\right) = \sum_{j=1}^{m} V_{s_{j}}
\end{align}
我们希望某种意义上——例如在学习过程中的任何一步或者都某个具体的第M步——成本最小,价值最大。
如果这些个体之间相互没有联系,则我们没有特别好的巧妙的办法,就是一个简单的优化问题。例如,我们可以先考虑两种极限:成本完全一样或者价值完全一样的情况。例如,前者,这个时候对于任何的\(\vec{S}\),\(C\left(\vec{S}, m\right)\propto m\),我们只能考虑优化\(V\left(\vec{S}, m\right)\)。于是我们发现,按照价值的递减顺序,也就是选择价值大的来先学就好。这时候能够保证在任何一步\(V\left(\vec{S}, m\right)\)都是最大的。更一般的成本函数和价值函数,应该,运筹学之类的学科也有答案了。如果没有,也无所谓,交给运筹学去解决好了。
更重要的问题是,一旦个体之间有联系,会如何?也就是说,一旦一个字\(j\)的学习难度会随着相联系的字\(i\)的学习状态(是否已经被学习到)而改变,这个时候,如何解决上面的优化问题。
那,我们先来看学习成本会如何变化。本质上,这个变化机制当然应该来源于实际学习过程。这里,我们先给出一个描述框架和大概描述。
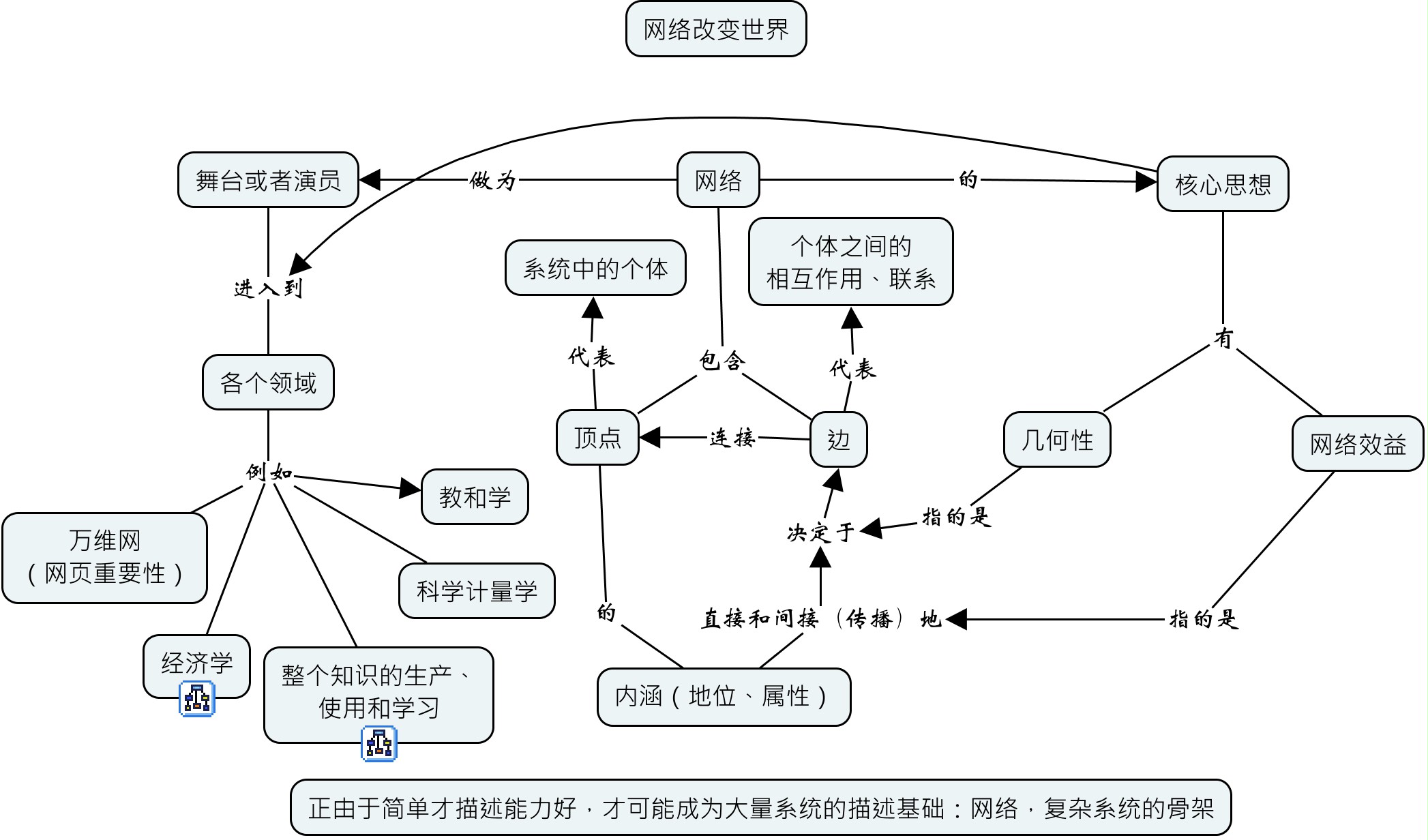
我们认为,概念之间的逻辑关系,可以做为关联的客观表现。以汉字为例,汉字之间通过结构关系相互联系,这一点是客观的(尽管繁体字和简体字在汉字之间是如何从结构上联系起来的这一点上不一样。先考虑例如仅仅简体字)。例如:木——林——森,人——从——众,水——冰——淼,(木,一)——本,(人,本)——体。当然,这个客观的结构联系是否就能代表逻辑联系,是有待讨论的。也就是说,在汉字集合上,存在着一个逻辑关系网络,网络的每一条边代表上面举例中的一个字\(i\)(更简单的字,处在更底层)成为另一个字\(j\)(更复杂的字,处在更上层)的一部分这样的结构关系\(A=\left(a^{i}_{j}\right)_{N\times N}\)(这个矩阵的标记采用的是投入产出习惯的符号,从\(i\)投入到\(j\)。)。这个结构关系上面叠加了一层逻辑关系。这个逻辑关系可以用来改变学习成本。再次强调,这仅仅是一个理想模型。记每一个概念的当前状态——学到或者没有学到——为\(\vec{K}\left(t\right)\)或者每一个概念\(i\)的状态\(k_{i}\left(t\right)=\pm 1\)。例如,我们可以定义每一个字在当前时刻的学习成本为一个由网络结构和网络上各个顶点的当前时刻的状态决定的函数\(c_{i}=c_{i}\left(A,\vec{K}\left(t\right)\right)\),而\(\vec{K}\left(t\right)\)实际上是学习顺序\(\vec{S}\)的函数。于是,学习成本\(C\)和学习成果\(V\)都是学习顺序\(\vec{S}\)的函数。当然,这个函数由于有网络关系,比完全没有联系的情况要复杂。但是,给定网络\(A\),那么\(C\left(\vec{S}, m; A\right)\)和\(V\left(\vec{S}, m; A\right)\)就是完全确定的函数,就可以讨论优化问题。下面给出一种我们使用过的成本决定机制。
- 认识下层字\(j\),以一定的概率降低上层字\(i\)的学习成本,\(\omega^{j, \left(\uparrow\right)}_{i} \),和结构矩阵的元素\(a^{j}_{i}\)有关。原则上可以不遵循结构矩阵,来自于其他实证关系。做为一个简化模型,我们可以假设\(\omega^{j, \left(\uparrow\right)}_{i} = 0 \mbox{或者} a^{j}_{i}\)。更复杂的需要考虑理据性。
- 认识上层字\(j\),以一定的概率降低下层字\(i\)的学习成本\(\omega^{j, \left(\downarrow\right)}_{i} \),和结构矩阵的元素\(a^{i}_{j}\)有关。原则上可以不遵循结构矩阵,来自于其他实证关系。做为一个简化模型,我们可以假设\(\omega^{j, \left(\downarrow\right)}_{i} = 0\)。更复杂的需要考虑理据性。
- 有了这个改变学习成本的概率,我们再来看学习成本改变的值。采用递归定义:
\begin{align}
c_{i}\left(t\right) = \left(1-k_{i}\right) \cdot \left[\Pi_{u}\left(1-k_{u}\omega^{u,\left(\downarrow\right)}_{i}\right)a^{i}_{u}\right]\cdot \left\{1+\sum_{d}\left(1-k_{d}\omega^{d\left(\uparrow\right)}_{i}\right) \cdot \left[1+\left(1-k_{d}\right)c_{d}\left(t\right)\right]a^{d}_{i}\right\}.
\end{align}
第一项的含义是,如果字\(i\)本身是学习过的,也就是\(k_{i}=1\),则\(c_{i}\left(t\right)=0\)。第二项的含义是,每一个字\(i\)上层字\(u\)如果学习过,则会成比例地降低字\(i\)的学习成本。第三项表示字\(i\)的学习成本包含三项——整体组合成本(按照单位一算),有几个子结构,每一个子结构如果不认得的话成本的累计。同时,如果下层的字学习过,则整体上会按照降低成本的几率再次降低子结构的成本(那时候子结构自己已经认得了,没有学习成本了)。由于采用了递归定义,整个网络不能有循环。其次,递归的每次都是从当前需要算成本的开始,然后往下计算——递归表达式中仅仅出现了往下的顶点的学习成本。
我们在Efficient learning strategy of Chinese characters based on network approach中的成本更新机制实际上就是上面的一般表达是的简化模型:
\begin{align}
c_{i}\left(t\right) = \left(1-k_{i}\right) \cdot \left\{1+\sum_{d}\left[1+\left(1-k_{d}\right)c_{d}\left(t\right)\right]a^{d}_{i}\right\}.
\end{align}
就算在这个简化机制下,我们也没有精确求解开这个优化问题。而是,基于对问题的理解,提出了一种近似算法:顶点权分配算法——后来我们发现实际上是一种广义投入产出分析计算。
现在,我们有了一个结构网络\(A\),两个这个网络上的逻辑关系\(\Omega^{\left(\downarrow\right)}, \Omega^{\left(\uparrow\right)}\),有一个学习顺序\(\vec{S}\),一个依赖于学习顺序的成本更新机制\(M\left(\vec{S}\right)\left|\right._{\vec{C}\left(t-1\right)\rightarrow \vec{C}\left(t\right)}\),以及初始条件\(\vec{C}\left(0\right)\)。还有一个价值变量\(\vec{V}\left(t\right)\),或者更复杂一点一个可能依赖于学习顺序的价值更新机制——这里当做价值不更新。
问:什么样的学习顺序\(\vec{S}\),会使得整个学习过程、在这个过程中的某个时间点m、或者在某个时间点m之前的过程中的学习效率最高——例如用平均每个字的学习成本来衡量。也可以为了学习到给定学习对象集合\(T=\left\{t_{1}, t_{2}, \cdots\right\}\)里面的所有的字的整体成本。