见http://www.bbc.com/future/story/20130315-a-better-way-to-learn-chinese。述评写的非常好,比我们的文章的Introduction还要好。Philip Ball是牛人一名(Critical Mass等书的作者)。
顺便,把我们汉字的工作也在这里总结一下。
研究问题
在这个用系联性思维和网络分析研究汉字学习的工作中,我们主要关心以下两个问题:第一、对于一个或者一类学习者来说,用什么顺序学习汉字学习效率会更高;第二、如何高效率地检测一个学习者认得哪些汉字。实际上,在这个工作中,我们仅仅完成了第一个问题的一部分。当然,数据和研究方法都可以用来研究第二个问题。
如果每一个汉字是独立的,那么,最好的顺序就是按照汉字的使用频率来学习:使用频率越高的汉字越早应该被学习。这样的话,经过一段时间的积累,我们就可以通过自己看书学习的方式来学习新的汉字。但是,汉字是独立的吗?
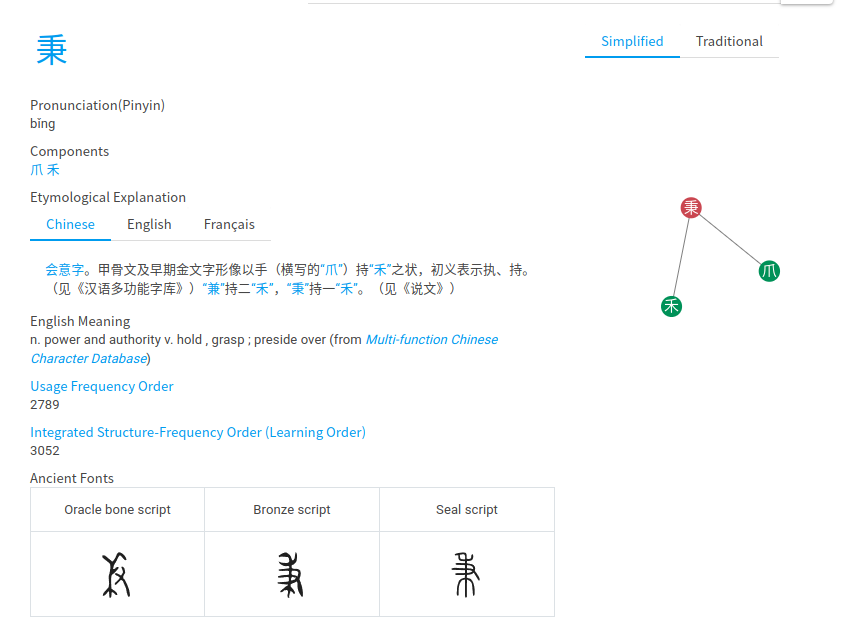
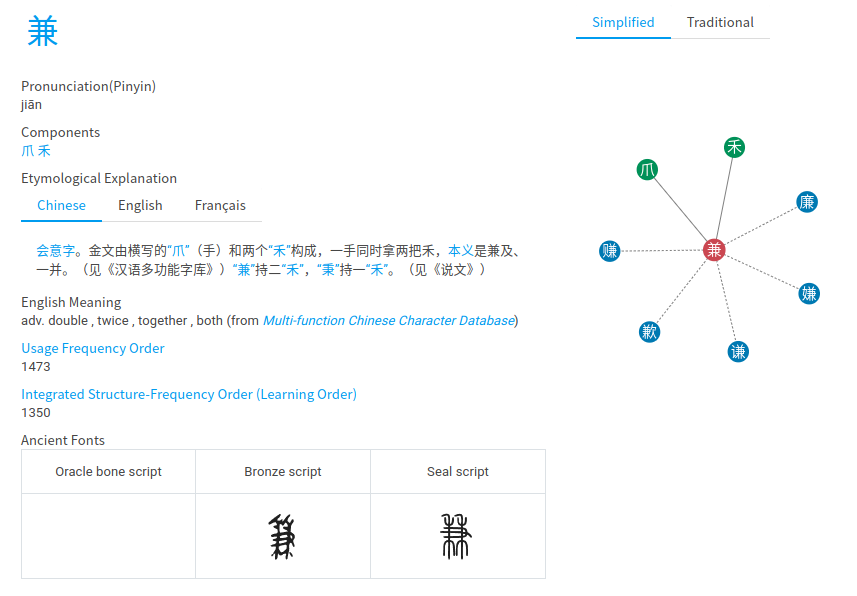
不是的,汉字的音形义之间有联系,不同的汉字之间也存在音形义的联系。例如,“木、林、森”,一棵树(木),聚在一起是一堆树(林),大范围聚集是一大片树(森)。。再例如“秉”是手、禾的结合表示“拿在手上”的含义,“兼”是并(两个禾苗)、手的结合表示“一手拿着两个禾苗也就是两样东西”的含义。通过字形的联系,我们看到了含以上的联系。
顺便,我们可以看到,如果我们先学习木,再学习林和森,以及先学习禾、手,再学习秉,接着学习兼,就可以很容易学会这些字。反过来,如果打乱这个顺序,或者说,每个字都单独记忆,则学习成本会高很多。同样地,如果你不认识木,我可以以很大的概率推测你也不认识林和森,或者反过来你认得森,我可以以很大的概率推断你认识林和木。这就是我们在下面的整个研究工作的最朴素的思考地点。
那么,既然汉字之间是相互联系的,汉字的音形义也是相互联系的,汉字学习和汉字检测是否能够利用上这样的联系呢?这时候,我们就需要把这些联系用一个数学结构来描述,然后,最好这个数学结构还能够帮助我们来解决更好的汉字学习顺序和汉字检测方法的问题。
数学模型
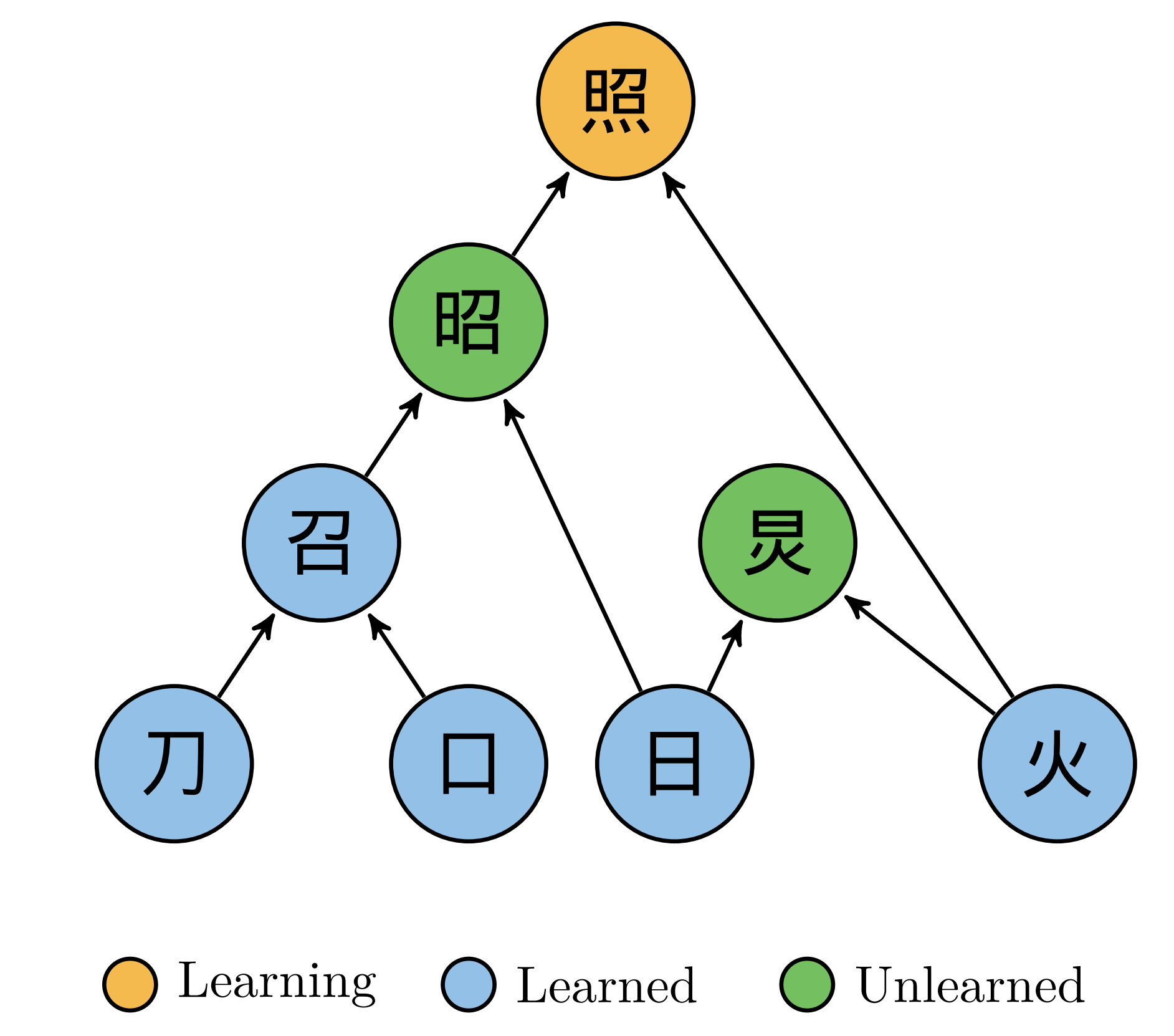
在我们的论文中,我们用了“网络”这个数学结构来描述汉字之间的关系。例如,下图就是“照”的一个局部的网络。我们做了直接联系的拆分,并且保持拆分出来的每个部分还具有表达音或者义的作用。注意,这里的拆分不是偏旁部首拆分,也不是笔画拆分。我们称之为汉字的理据性拆分。
有了这个拆分的原则之后,我们就可以对所有的汉字做拆分,得到汉字结构地图(这个基础数据是四人年的工作量哦,而且我们都仅仅是做整理——把前人研究好的每一个字到底应该如何拆分有什么道理整理成比较有系统的一个数据库——而已),见下图。
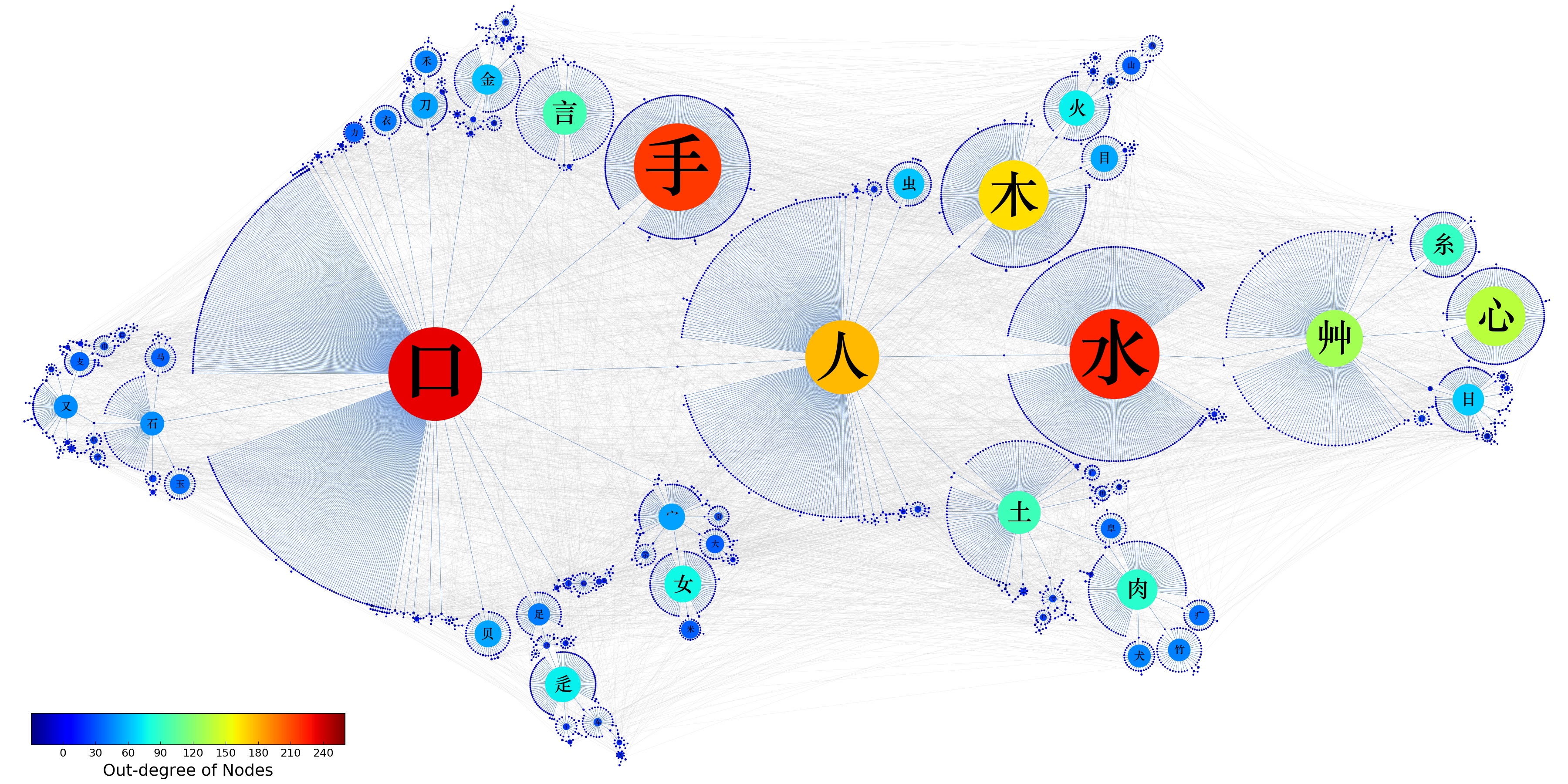
那现在有了描述汉字联系的数学结构(记做矩阵\(A\),其中元素\(a^{i}_{j}=1\)表示汉字\(i\)成了汉字\(j\)的一部分,否则\(a^{i}_{j}=1\))了,这个结构能够帮助我们通过计算来解答前面的两个问题吗——更好的汉字学习顺序、更好的汉字检测算法?直觉上来说,在汉字学习上,我们需要一个“学习了汉字A可以帮助我们更容易更好地学习汉字B”的关系,比如说,写成\(C\left(B=0\rightarrow B=1|A=1\right)\),以及更加一般的多个汉字之间的学习上的依赖关系\(C\left(B=0\rightarrow B=1|A_{1}=1,A_{2}=1\right)\)。直觉上来说,在汉字检测上,我们需要一个“检测得到汉字A认得(不认得)可以推断出来汉字B认得或者不认得的概率”,比如说,写成\(P\left(B=1|A=1\right), P\left(B=0|A=1\right), P\left(B=1|A=0\right), P\left(B=0|A=0\right)\),以及更加一般的多个汉字之间的是否认得上的依赖关系\(P\left(B=1|A_{1}=1,A_{2}=1\right)\)等等。
这个依赖关系可以从上面的汉字结构地图或者说汉字网络上得到吗?大概来说可以。我们可以把连边连起来的汉字这样来看:学习下一层的更简单的汉字可以帮助我们降低学习上层汉字的成本(具体如何降低是另一个问题),这样就大概得到了\(C\)函数;如果检测了下层汉字不认得,则上层汉字以很大的概率可以推断不认得,检测了上层汉字认得,则下层汉字以很大的概率可以推断认得,这样就得到了\(P\)函数。由于学了基本字可以降低学习复杂字的成本,这样的\(C\)函数有一个特性:从底向上学起来节省成本,跳着学成本更高。
有了这两个函数,原则上,我们就成了一个数学题:给定任何一个学习顺序,我们可以计算出来从成本;给定一个检测顺序(检测算法),我们可以计算出来需要检测多少次才能达到某个误差范围内,于是下一步就是一个优化问题:既然成本都能够计算出来,则,是否存在并且能够(近似)找到一个最优的学习顺序和检测顺序(检测算法)。
在这个工作中,我们用一个近似方法——顶点权传递方法(后来我们发现这个方法是广义投入产出分析的一种,和PageRank类似)——求解了第一个问题。我们把我们的算法得到的学习顺序的度量称作“分布式顶点权”。其基本思想特别简单:给每一个汉字一个原始顶点权——其使用频率(\(W\));从最上层开始,把原始顶点权往下传播到它们的下一层,传播之后,下一层的分布式顶点权(\(\tilde{W}\))等于其原始顶点权加上从上面传下来的那些乘以个系数,然后继续传递到下一层,也就是
\begin{align}
\tilde{W}^{i}= W^{i} + \sum_{j}\frac{a_{i}^{j}}{\sum_{k}a_{i}^{k}}\tilde{W}^{j}.
\end{align}
或者说用更简单的记号,记\(B^{i}_{j}=\frac{a_{i}^{j}}{\sum_{k}a_{i}^{k}}\),则
\begin{align}
\tilde{W}= W+ B\tilde{W} \Rightarrow \tilde{W}= \left(1-B\right)^{-1}W.
\end{align}
注意这个公式跟论文中不完全一样,时候来根据广义投入产出分析的思想修改过的公式。
有了这个算出来的“分布式顶点权”,我们就可以给所有的汉字排个序,权大的优先学习。于是,就得到了一个可能比较好的学习顺序。注意,我们没有去求精确解,这个解是基于一些简单理念猜出来的。这些简单理念包含:越下层的简单字应该越优先学习,使用频率大的字优先学习,参与构字数量多的字应该优先学习。我们猜出来上面的传播计算正好符合这三个理念。
结果和结论
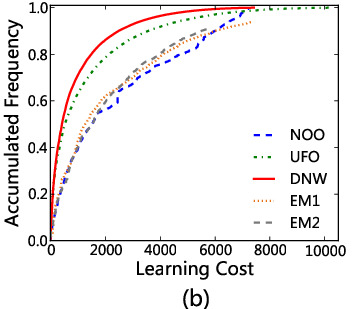
那,怎么检验呢?原则上要通过实践检验,因为前面的学习成本函数\(C\)也是不可靠的。但是,只要有了\(C\)函数,我们就可以理论上先来比较一下几个不同的学习顺序,例如,不同教材上的学习顺序,我们算出来的顺序。于是,我们得到了下面的两张图。我们发现。无论是以总字数还是总使用频率为目标,我们的分布式顶点权的顺序学习效率都比较高(成本比较低)。当然,如果仅仅看字数,则从底向上学习肯定是最节省成本的,但是,可能会学习一大堆非常用字;如果仅仅看使用频率,则按照使用频率学肯定不差,西瓜先捡大的吃。但是,我们算出来的顺序竟然在两方面都不差,甚至,在使用频率上,由于照顾了上下层关系,比其他的都好。当然,你会发现,实际教材的,远远赶不上这些理论模型。这说明,这些实际教材在设计的时候基本上没有考虑汉字学习顺序的问题。

讨论和展望
当然,你说,这个\(C\)函数和\(P\)函数不够准确。是的,这个显然还可以继续提高。例如,是不是学习了上层汉字以后也可以降低下层汉字的学习成本,只不过可能效果没这么强?这些因素都可以在汉字网络的框架内进一步考虑进去。
甚至,更进一步,我们注意到实际上汉字学习和汉字检测的关键数学表达式非常像条件概率。考虑到汉字之间没有结构关系也可能会存在相互启发的作用,因此,汉字网络这个数学结构用来描述上面的\(C\)函数和\(P\)函数其实还不够。更好的数学结构是概率图模型。目前,我们正在开展这方面的研究。将来,通过实际汉字检测得到的汉字结构数据正好可以和这里的纯结构网络做一个对比。我相信,两个结构还是应该有很大的相同的部分的。
更加一般地,我们猜测,如果我们把所有的学科的概念都整理成为概念网络,或者说概念地图,则,我们可以用类似的方法来研究更好的学习顺序和更好的检测方法的问题。
我们看到,如果我们忽略这个汉字之间的、汉字音形义的联系,甚至进一步忽略汉字的使用频率,则,我们只能一个个随机地来学习汉字,一个个随机地来检测汉字。也就是说,我们对汉字这个集合的描述确实更简单了,无相互作用系统,但是,我们对于解决汉字学习和检测的问题的方法却也就更愚蠢了。
这个研究工作的原始数据、计算结果、完整的汉字联系(理据性)的解释见www.learnm.org。已发表的论文在这里:Xiaoyong Yan, Ying Fan, Zengru Di, Shlomo Havlin, Jinshan Wu, Efficient learning strategy of chinese characters based on network approach, PloS ONE, 8, e69745 (2013) DOI: 10.1371/journal.pone.0069745.